捕鱼游戏一多人就卡顿?先别急着加机器,这5个坑你可能踩了
上线前几十人测试顺滑得像开了挂,一上正式服立马掉帧、延迟飙到3秒起步,子弹打出去半天才“响”,鱼群跳得跟幻灯片似的——别慌,真不是你服务器不够猛,大概率是架构设计没想清楚。
我们做过上百个版本,被用户投诉逼到凌晨三点改代码,总结出来的经验就一句话:能扛万人同屏的,从来不是靠堆服务器,而是靠“把请求拦在门外、让数据跑得快、让系统少干活”这三板斧。
这些不是纸上谈兵,是血泪换来的实操结论。
1. 网络通信协议选错?别再用纯TCP了,真会拖死你
还在用原生TCP做游戏通信?那你就等着看“开枪指令发出去,两秒后才收到反馈”的奇观吧。更别说4G下直接变“木头人”,动不了也看不清。
问题在哪?TCP为了保序和不丢包,自动重传、排队,延迟越积越多。而捕鱼这种实时性极强的游戏,每毫秒都可能是胜负手。
✅ 正确打开方式:
底层用 UDP,延迟最低;
但原生UDP不保序也不重传,容易丢包;
所以得加一层 KCP(比如 Kratos KCP),它在UDP基础上做了智能重传、防抖、滑动窗口控制,既能低延迟,又能保证关键指令(比如开枪)必达。
实操建议:
客户端直接用现成的 KCP 封装库,别自己写协议栈,太容易翻车;
服务端推荐用 C 或 Go 写 KCP 服务器,千万别用 Java 阻塞式 IO,尤其是别拿 Spring Boot 的 Web 框架当游戏服务器用,性能拉胯还难调;
重要操作(开枪、命中)走可靠模式,动画同步这类非关键数据用不可靠模式,允许少量丢包,但不能影响主线逻辑;
注意:某些地区(比如东南亚),运营商对 UDP 流量限速很狠,哪怕用了 KCP,实际体验也可能差得离谱。本地部署或走 CDN 加速节点才是王道,否则等于白搭。
劝退提醒:如果你是以下情况,请立刻放弃自研网络层——
预算不到20万;
团队没人懂底层网络;
只想快速验证玩法;
→ 直接上成熟中间件,比如 Tars KCP 模块 或 ZeroMQ 自定义序列化,省下三个月试错时间,真香。
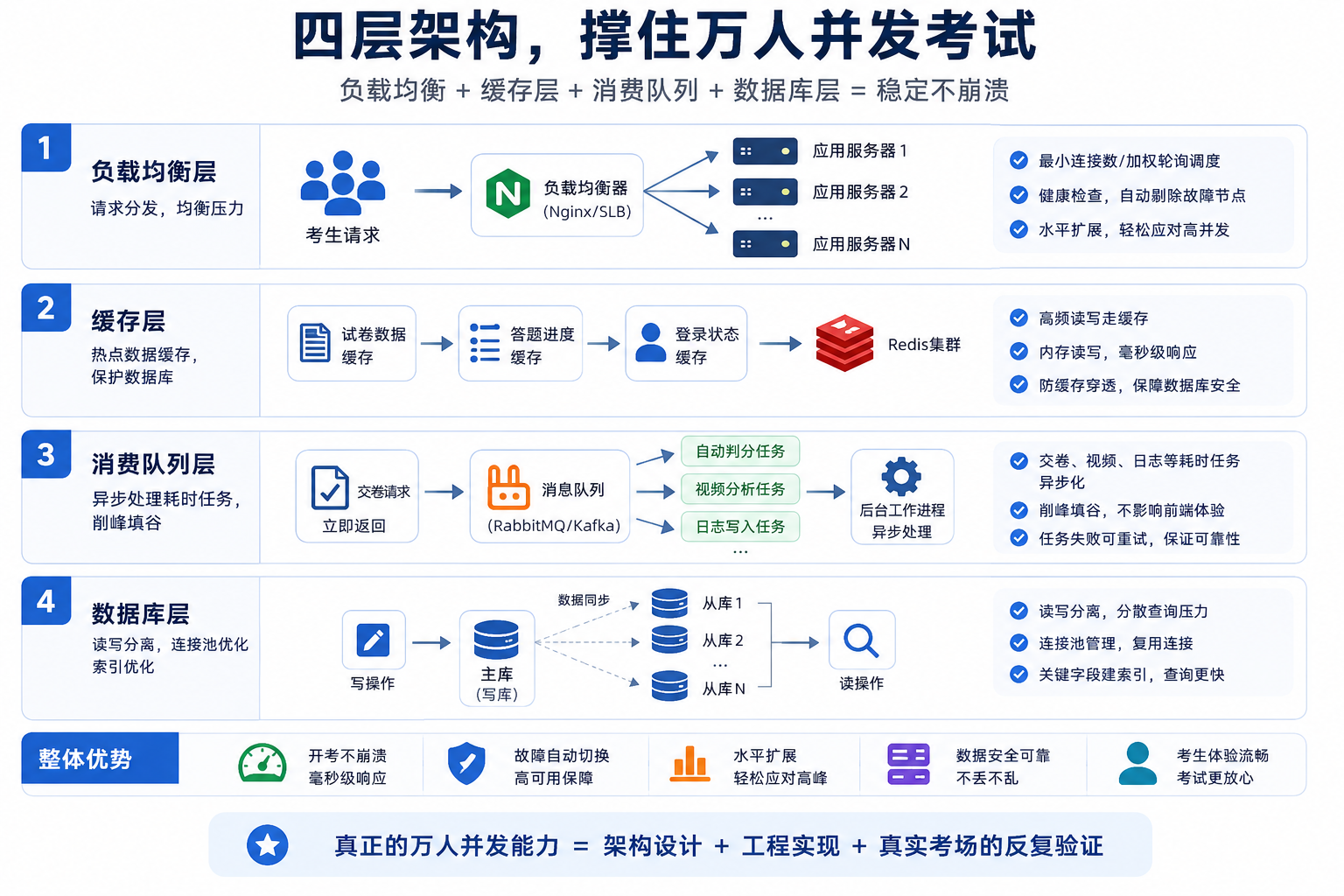
2. 服务器线程模型搞错了?一个线程干所有活,迟早崩
如果服务器是“一个线程处理所有客户端连接”,那一旦1000个玩家同时开枪,这个线程瞬间就被压垮,响应时间从10ms飙到500ms,用户直接骂街。
正确姿势:多线程 职责分离。
主接收线程(Acceptor):只负责接新连接,认证通过后立刻扔给工作线程;
工作线程池(IO线程):每个线程独立处理一个客户端的读写和数据解析;
任务队列:非实时操作(发金币、存日志)放进队列,后台异步处理。
实操建议:
用 Netty(Java)或 libuv(C )搭底座,别碰原生 Socket;
工作线程设8~16个,根据机器核心数调整,一般别超过核心数的2倍;
别用
synchronized锁全局变量,换成无锁队列(比如 Disruptor);特别提醒:高并发下,单个线程上下文切换成本极高。要是用 Java,必须配合 G1 GC 调优,不然垃圾回收一停顿,延迟直接炸裂。
业内共识:现在主流做法是“网关层 业务层分离”。网关管连接、鉴权、限流;业务层专注游戏逻辑。这样结构清晰,横向扩展方便,接入监控和风控也顺手。
平替方案:不想深入底层?可以用 Kubernetes Istio 搭微服务架构,每个玩家会话封装成独立实例,通过 Sidecar 注入流量控制策略。虽然成本稍高,但后期维护省心。
3. 数据同步太频繁?别瞎同步,该省就省
你是不是让每个客户端每秒同步10次鱼的位置?
→ 1万个玩家就是每秒10万次位置更新,服务器算不过来,内存爆了都不稀奇。
根本问题:玩家看到的只是“视觉延迟”,只要逻辑一致就行,没必要每帧都同步。
✅ 解法来了:
降低同步频率:
高性能设备(PC):30Hz 同步一次;
中低端手机:15~20Hz,减轻计算压力;
只同步变化部分:
鱼移动 → 只发“方向 速度”变化,不传完整坐标;
子弹命中 → 发“命中事件”,而不是整条轨迹;
用差量更新:客户端保存上次状态,只收“增量”。
实操建议:
服务端用
Redis缓存玩家当前状态(血量、分数),避免反复查数据库;用消息队列(如 Kafka / RabbitMQ)广播“事件”给相关玩家,别全量推;
让客户端自己插值补帧,减少服务器负担;
注意:差量更新对客户端要求高,如果插值没做好,会出现“鱼突然跳跃”现象,反而更影响体验。
常见误区:有人为了追求“极致同步”,把所有对象状态都用 WebSocket 推送,结果带宽爆炸。实际经验告诉我们,90%的玩家根本察觉不出100ms内的延迟差异,不如把资源用在防外挂和稳定性上。
平替方案:不想搞复杂同步?试试“事件驱动 状态快照”模式——每隔5秒发一次完整状态,其余时间只发变动事件。适合中小型项目,风险低,见效快。
4. 外挂和作弊太多?别让垃圾请求拖垮系统
外挂玩家点一下鼠标,服务器收到10条“开枪”指令;
或者伪造坐标,一秒打死大鱼。
这些请求看着像正常行为,其实是垃圾流量,占着本该服务正常玩家的资源。
✅ 防御策略:
客户端校验:所有关键操作(开枪)必须经服务器验证;
行为检测:
1秒内开枪超3次 → 暂时封禁;
坐标跳跃距离过大(>10米/秒)→ 视为外挂,标记并上报;
接入风控系统:用 Redis Lua 脚本快速判断异常请求。
实操建议:
在网关层加限流,比如 Nginx Lua,限制单个IP每秒最多10个请求;
对疑似外挂账号,强制走验证码流程;
关键点:别只靠“黑名单”,要建动态评分机制。同一个账号频繁换设备、登录失败、异常时间段活跃,都要打标签。
行业真相:外挂不可能完全防住,但可以做到“让外挂成本远高于收益”。比如检测快、封号快、恢复难,多数人就不玩了。有些团队甚至故意留点小漏洞,让外挂能用,但代价太大,最后没人愿意投入。
平替方案:预算有限?直接用云厂商的 WAF Bot Manager(阿里云、腾讯云都有),自带行为分析能力,比自己写规则靠谱多了。
5. 代码没优化?渲染和碰撞太耗性能
你以为“画几条鱼、打几颗子弹”很简单?真到了1000人同时在线,物理碰撞、粒子特效、贴图加载全堆在一起,服务器直接崩。
✅ 优化方向:
批量处理:别一个个判断子弹是否击中鱼,用 空间网格算法(Grid System)把场景分块,只检查格子里的物体;
对象池复用:子弹、鱼、爆炸特效用对象池管理,避免频繁创建销毁;
简化逻辑:低端设备上关闭水波纹、光影等特效。
实操建议:
用 Unity 做客户端时,记得开 Batching(合并绘制);
用 Cocos 引擎时,注意 合图 和 裁剪;
服务端只保留必要状态,图形渲染交给客户端;
特别提醒:空间网格的分块大小很关键。太小会导致频繁跨格检查,太大又失去效率。经验值是10×10米一块,根据地图大小调。
隐藏坑点:用了空间网格后,需要额外维护格子索引表。如果玩家移动太快,可能漏掉格子更新,导致命中判定错误。必须加定时器补偿机制,不然就出事。
平替方案:不想搞复杂碰撞?用“区域广播 快速过滤”——只通知附近玩家,不主动扫描所有对象。适用于中等规模场景,简单稳定。
关键防坑提示:别踩这4个雷区
❌ 把所有玩家状态存在内存里,不持久化 → 重启就丢数据,用户投诉“账号没了”;
❌ 用 MySQL 做实时同步 → 读写慢,高峰期锁表,连不上;
❌ 依赖“一键部署”工具包 → 没监控、没日志、没报警,出问题找不到原因;
❌ 忽视弱网环境 → 4G下体验差,用户直接卸载。
✅ 正确做法:
用 Redis 存玩家状态,MySQL 存历史记录(充值、战绩);
用 Prometheus Grafana 做监控,看每秒请求数、延迟、连接数;
部署时加 Nginx 反向代理 负载均衡,支持横向扩展;
补充:真实环境中,70%的延迟问题来自客户端而非服务器。建议在客户端埋点,收集网络质量、帧率、卡顿次数,才能精准定位问题。
FAQ 常见问题解答
Q:我只有100个玩家,用KCP会不会太复杂?
A:不会。哪怕100人,也建议提前练好低延迟架构。等真上万人,你才不会手忙脚乱。测试阶段用 TCP 简单心跳过渡也行,但别养成依赖。
Q:能不能用 Python 做捕鱼游戏服务器?
A:可以,但仅限小规模测试。生产环境强烈建议用 C /Go/Java。Python 无法承受高并发,除非你用 asyncio C 扩展,否则连500个连接都撑不住。
Q:外挂真的能被完全防住吗?
A:不能。但你可以做到“让外挂成本远高于收益”——检测快、封号快、恢复难,大多数人就不玩了。有些团队甚至故意留点小漏洞,让外挂能用,但代价太大,最终没人愿意投。
Q:要不要用云服务器?
A:必须用。推荐腾讯云、阿里云的弹性伸缩实例,能根据流量自动扩容,省心又省钱。切记别买固定配置的虚拟机,遇到突发流量只能硬扛。
Q:有没有现成的开源项目可以直接用?
A:有,比如 GitHub 上的 Fishing-Game-Source-Code,但注意:源码只是骨架,架构设计才是灵魂。你得自己改网络层、加风控、调性能。
真实评价:这类项目大多只跑通了“单机版”,一上多人就崩溃。别指望拿来即用,顶多当个参考文档。