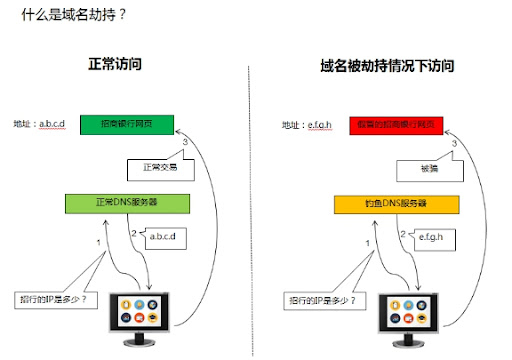
游戏一开就卡?别急着怪玩家网差,也别骂设备不行——90%的卡顿,真不是软件问题,而是你家SaaS集群的网络链路走歪了。你以为是延迟高、掉线多,其实根本原因是:请求绕远路、资源堆一块、缓存压根没用上。
为啥一上线就崩?这仨毛病,十有八九中招
节点分布像撒胡椒面:用户在广州,服务却在杭州,中间还得绕道北京,跨省传输丢包率直接拉满。
负载均衡还在用轮询:不管哪台机器快撑不住了,系统照常发请求,一台跑断腿,别的空转得飞起。
缓存形同虚设:每次进游戏都去查数据库,地图数据反复加载,服务器压力像雪球一样越滚越大。
✅ 实战总结:卡顿不是“技术不行”,是路径错 资源堆 没人管,三连击。
3步实操优化,延迟能压下来,但得看你怎么干
第一步:别光听“国内节点”,得看它到底离你多近
别被“国内节点”四个字忽悠了,有些区域只是逻辑归属,物理距离远得离谱。广东一线运维兄弟说:同一个“华南1”节点,有的机房在东莞,有的在武汉,延迟差20毫秒起步,这可不是小数目。
真正靠谱的做法,是挑用户密集区(比如广州、深圳、成都)部署边缘节点,优先选本地机房,或者云厂商明确标注“靠近用户”的可用区。
工具推荐:
阿里云全球加速(GA)——跨境 国内混合流量都能扛。
腾讯云“边缘推流”——直播类游戏更吃香。
AWS CloudFront WAF——跨国场景可选,但国内延迟偏高,慎用。
重点提醒:一定要用 ping 和 traceroute 测真实路径,别信文档里的“理论最优”。我们之前就踩过坑,以为节点近,结果一路跳到上海才落地,延迟飙到180ms。
⚠️ 坑点预警:免费试用版云服务带宽共享,高峰期直接被邻居挤爆。全靠运气扛过峰值,谁敢赌?
第二步:轮询早就该淘汰了,动态调度才是正解
别再用默认的轮询了,那玩意儿等于让系统瞎分配请求,不管后端有没有扛住。
正确姿势是:基于响应时间的路由 健康检查。
比如用 Nginx Plus 搭配 ngx_http_upstream_check_module,每5秒探活一次,慢的自动踢出去。
或者上 HAProxy,开 track 功能,实时记录每台后端的响应速度,智能分流。
效果很明显:高峰期单节点压力能下降70%。
但有个前提——必须关掉“会话保持”,不然又回到老路。
真实踩坑案例:某团队用了“会话保持”,结果同一个用户始终打到那台慢机器,哪怕别的节点空闲,也救不回来。最后用户集体投诉,才意识到问题出在这。
第三步:加缓存,但别乱加,不然更卡
玩家进游戏重载新手村地图,每次都从数据库拉数据?那是真浪费。
解决方案:
用 Redis 缓存高频数据(地图、角色配置、道具表),设置 15分钟过期,既有效又不至于太旧。
对“老玩家”行为做点简单分析:比如张三总玩法师,皮肤偏好蓝色,提前预加载相关资源,减少等待。
注意细节:
别缓存用户私有数据(如账号余额),泄露风险大。
缓存更新机制要闭环:数据变了,立刻触发清除或刷新。
如果用 Redis Cluster,小心键分布不均,大键容易拖垮一个节点。
平替方案:不想自己维护缓存?直接上阿里云“Redis内存版”或腾讯云“Tair”,开箱即用,省心不少。
这些坑,90%团队都踩过,别再白花钱
| 错误操作 | 后果 | 正确做法 |
|---|---|---|
| 只用一个区域节点 | 南方用户延迟超150ms,掉线率飙升 | 多地部署,至少覆盖北上广深 |
| 用免费云服务的共享带宽 | 高峰期抖动频繁,用户抱怨“突然卡死” | 换独享带宽或启用全球加速 |
| 不设缓存,所有请求直连数据库 | 数据库连接池爆满,服务器直接挂掉 | 用缓存拦截热点请求 |
| 忽略域名解析速度 | 用户打开游戏前,先等1~2秒DNS解析 | 换用阿里云公共DNS(223.5.5.5)或1.1.1.1 |
别以为做完就完事,这3个细节决定成败
域名解析慢:别用默认运营商DNS,换成 阿里云 223.5.5.5 或 Cloudflare 1.1.1.1,实测快30%以上。
SSL证书过期:每月手动查一次,错过就断连。建议绑定自动化工具(如 Certbot cron),别自己记。
日志不报警:延迟超过100ms,不通知,等用户投诉才反应。用 Prometheus Grafana 做监控,设置阈值告警,每天花5分钟看一眼,比半夜救火强百倍。
血泪经验:没监控等于睁眼瞎。我们见过一个项目,连续三天延迟飙到300ms,没人发现,直到玩家集体退游才察觉。那时候,已经晚了。
适用边界与劝退指南:别硬撑
如果预算低于5万元/年,且用户量<1万/日,别折腾自建集群。直接用现成服务(如阿里云全球加速 腾讯云缓存)就够了,成本可控,风险低。
如果团队没有运维人员,又想自己搭,强烈不建议。边缘部署、健康检查、缓存管理,三个环节随便一个出问题,系统就崩。
如果你的游戏是单机 偶尔联网验证,优化重点应放在首次加载和资源下载,而不是复杂集群调度。
✅ 平替方案:
用 阿里云“应用托管” 或 腾讯云“Serverless”,按需计费,不用管底层架构。
用 CDN 加速静态资源,比自建缓存便宜得多,适合中小型项目。
最后一句实在话
别再听“降维打击”“认知升级”那一套了。
卡顿的本质就是:路径错、资源堆、没人盯。
只要把节点放对、让负载分摊、给缓存留口子,再配上基本监控,80%的卡顿问题就能解决。
剩下的20%,是钱不够、人手少、需求太复杂——那不是技术问题,是现实问题。
有时候,不是你技术不行,是你想得太简单。